












【佳学基因检测】一种利用下一代测序进行差异甲基化基因座的基因检测方法
高通量测序与甲基化基因检测导读
表观遗传变化,尤其是 CpG 基因座的 DNA 甲基化,对dota2吧雷电竞 和其他复杂疾病具有重要意义。随着下一代测序(NGS)的发展,使用病例对照设计生成数据以了解全基因组基因座甲基化状态的差异是可行的。佳学基因解码为此设计了适当和有效的统计检验,以解决这一基因检测技术所遇到的困难。首先,与使用微阵列的甲基化实验不同,其中在特定 CpG 位点对一个个体进行甲基化测量。佳学基因所采用的甲基化测序与新一代测序技术应用拓展重大课题组有每个个体的甲基化等位基因和非甲基化等位基因的计数。其次,由于样品制备的性质,测量的甲基化反映了样品制备中涉及的细胞混合物的甲基化状态。所以,测量的甲基化水平的潜在分布是未知的,稳健的测试比参数方法更可取。第三,目前高通量测序测量超过 200 万个 CpG 位点的甲基化。任何统计测试都必须具有计算效率,才能应用于 NGS 数据。考虑到这些挑战,甲基化测序与新一代测序技术应用拓展重大课题组通过对甲基化计数进行建模,提出了基于聚类数据分析的差异甲基化测试。甲基化测序与新一代测序技术应用拓展重大课题组进行了模拟以表明它在测量的甲基化水平的几个分布下是稳健的。它具有良好的功能并且计算效率很高。贼后,甲基化测序与新一代测序技术应用拓展重大课题组将该测试应用于甲基化测序与新一代测序技术应用拓展重大课题组关于慢性淋巴细胞白血病的高通量测序数据。结果表明,这是一个很有前途和实用的测试。
高通量测序与甲基化基因检测关键词:
DNA甲基化,甲基化差异检测,二代测序
甲基化测序基因检测科普介绍
近年来,由于基因分型技术的快速进步和人类基因组计划的完成,基因检测关联研究,尤其是大规模的全基因组基因检测关联研究变得非常流行。通过全基因组关联研究已经确定了数百个疾病的易感基因座。尽管取得了这一进展,并建立具有一定规模的数据库。但迄今为止鉴定的遗传变异仅解释了大多数复杂疾病的一小部分表型变异 。表型变异的另一个潜在来源是表观遗传变化,例如 DNA 甲基化。
DNA甲基化是指在CpG二核苷酸中胞嘧啶的5'端添加一个甲基。启动子区域的 DNA 甲基化可以抑制基因的表达。已经表明 DNA 甲基化变化与许多人类疾病有关,尤其是癌症。CpG二核苷酸的高甲基化是dota2吧雷电竞 抑制基因失活的重要标志。相反,正常甲基化基因的低甲基化可能导致癌基因的激活。基因解码中的人类表观基因组检测是研究全基因组表观遗传模式 。
随着生物技术的发展,现在可以通过下一代测序 (NGS) 对全基因组 CpG 位点获得生成甲基化数据。在这些基因解码过程中,DNA 样本用亚硫酸氢盐处理,它将未甲基化的胞嘧啶转化为尿嘧啶,并使甲基化的胞嘧啶保持完整。NGS 对每个受试者或样品的每个 CpG 位点处具有胞嘧啶(甲基化)的分子数和具有尿嘧啶(未甲基化)的分子数进行计数。
基于来自高通量测序基因检测的计数来测试组(例如,病例和对照)之间差异甲基化的一种简单方法是对给定 CpG 位点的组内受试者的计数求和,从而产生 2 × 2 列联表(甲基化/未甲基化 × 病例/对照)。然后将 Pearson 的独立性卡方检验用于此表。这种方法是有问题的,因为每个个体的测序覆盖率(测量的总分子数量较大)可能不同,导致测序覆盖率大的个体对测试统计数据产生不当影响。此外,该测试没有考虑甲基化水平的受试者间变异性。
另一种方法是首先估计每个个体每个 CpG 位点的甲基化比例 ( β ), β = n methy / ( n methy + n unmethy )。然后可以对β应用t检验。这种方法消除了先前方法中覆盖率不均的问题,并且该测试还考虑了甲基化水平的受试者间变异性。然而,这种方法存在几个问题。首先,与甲基化微阵列实验获得的数据不同,在直接测量甲基化比例的情况下,甲基化比例是根据高通量测序的计数数据估计的。测序覆盖率的差异将导致β估计值的正确性不同,测序覆盖率越大的受试者估计β的标准误差越小。这种异方差性对于t检验可能是有问题的。此外,t检验的正态性假设可能不适用于高通量测序甲基化数据。除了测序覆盖率的影响外,甲基化比例还可能受文库制备、批次效应等诸多因素的影响。这些附加因素会影响真实β在样本或受试者上的分布,因此这种分布是未知的。因此,需要一个稳健的t检验替代方案。使用t检验分析甲基化比例的另一个问题是t检验定义在 -∞ 到 ∞ 之间,而甲基化比例限制在 0 和 1 之间。在实际数据中,甲基化测序与新一代测序技术应用拓展重大课题组观察到相当大比例的样本和 CpG 位点具有甲基化比例等于 0 或 1。在本文中,甲基化测序与新一代测序技术应用拓展重大课题组提出了一种基于聚类数据分析的检测差异甲基化 CpG 位点的测试,方法是直接对甲基化计数进行建模。然后甲基化测序与新一代测序技术应用拓展重大课题组进行了模拟以表明所提出的测试在测量的甲基化水平的几个分布下是稳健的。
高通量测序甲基化测序的基因解码方法
建立模型
在这里,甲基化测序与新一代测序技术应用拓展重大课题组在病例对照研究设计中对甲基化计数进行建模。假设案例组中有n A个人,对照组中有n U个人。甲基化测序与新一代测序技术应用拓展重大课题组有k个 CpG 位点的 NGS 全基因组甲基化数据。设m Aij是个体i在 CpG 位点j的甲基化读数的计数,c Aij是个体i在 CpG 位点j的覆盖率,β Aij是个体i在 CpG 位点j的真实甲基化水平情况下,甲基化测序与新一代测序技术应用拓展重大课题组对m进行建模具有二项分布的Aij
m Aij ~ B ( c Aij , β Aij ), i = 1, ... n A , j = 1, ... k。
(1)
类似地,甲基化测序与新一代测序技术应用拓展重大课题组将m Uij、c Uij和β Uij定义为控件中的对应量,甲基化测序与新一代测序技术应用拓展重大课题组有
m Uij ~ B ( c Uij , β Uij ), i = 1, ..., n U , j = 1, ... k。
(2)
这里的关键是将高通量测序读取视为每个个体中的集群,问题变成在存在集群数据的情况下比较两个比例。这些集群是实验设计的自然结果,也是对每组内每个受试者测量的二项式数据的性质。为此,甲基化测序与新一代测序技术应用拓展重大课题组采用了聚类数据分析的方法。这种方法首先计算设计效果,然后用于调整病例和对照中的甲基化比例。
模拟研究
在每种情况下,甲基化测序与新一代测序技术应用拓展重大课题组分别使用如上模拟的甲基化比例,根据方程 (1)和(2)模拟病例和对照的甲基化分子计数。甲基化测序与新一代测序技术应用拓展重大课题组允许覆盖率c Aij和c Uij通过从贼小为 5 的正态分布N (30, 13) 中采样而变化,这是甲基化测序与新一代测序技术应用拓展重大课题组在下面分析的实际数据中使用的贼小读取次数。
结果
甲基化测序与新一代测序技术应用拓展重大课题组在H 0下进行了模拟,以研究所提出测试的 I 类错误率。如上一节所述,甲基化测序与新一代测序技术应用拓展重大课题组考虑了甲基化水平分布的三种情况。对于每种情况,甲基化测序与新一代测序技术应用拓展重大课题组模拟了病例和对照中相同数量个体的甲基化计数。甲基化测序与新一代测序技术应用拓展重大课题组将n A = n U设置为从 10 到 500 的不同数字,以研究样本量的影响。在每个场景中,甲基化测序与新一代测序技术应用拓展重大课题组对每个样本大小进行了 100,000 次重复。表一给出了在场景 (a) 的几个α水平上评估的经验 I 型错误率,其中单个甲基化水平是从 β 分布产生的。相似地,表二给出场景 (b) 的经验 I 型错误率,其中单个甲基化水平是从正态分布产生的,并且表三给出了场景 (c) 的经验 I 型错误率,其中单个甲基化水平是从混合正态分布产生的。从这些表中可以看出,随着样本量的增加,I 类错误率接近标称α水平。这适用于所有α水平和所有三种甲基化水平分布。与三种模拟情景相比,当甲基化水平服从正态分布时,I 型错误的膨胀低于甲基化水平服从 β 或混合正态分布的情景。当甲基化水平遵循情景(c)中的混合物正态分布时,通货膨胀贼高。
表一:模拟场景 (a) 的 I 类错误率
|
样本量 |
检验 |
α = 0.05 |
α = 0.01 |
α = 0.001 |
α = 0.0001 |
|
10 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.07747 |
0.02564 |
0.0067 |
0.00217 |
|
t检验 |
0.09458 |
0.04886 |
0.01629 |
0.00386 |
|
|
幼稚的 |
0.24474 |
0.13104 |
0.05517 |
0.024 |
|
|
20 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.06425 |
0.01765 |
0.00295 |
0.00069 |
|
t检验 |
0.07798 |
0.0274 |
0.00923 |
0.00402 |
|
|
幼稚的 |
0.25003 |
0.13357 |
0.05735 |
0.02437 |
|
|
50 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.0548 |
0.0128 |
0.00172 |
0.00024 |
|
t检验 |
0.06759 |
0.02646 |
0.0101 |
0.0041 |
|
|
幼稚的 |
0.25753 |
0.14062 |
0.06116 |
0.02628 |
|
|
100 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05299 |
0.01132 |
0.00128 |
0.00012 |
|
t检验 |
0.05941 |
0.01566 |
0.00286 |
0.00064 |
|
|
幼稚的 |
0.26273 |
0.14285 |
0.06193 |
0.02766 |
|
|
500 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05096 |
0.01022 |
0.001 |
0.00014 |
|
t检验 |
0.05704 |
0.01635 |
0.00375 |
0.0011 |
|
|
幼稚的 |
0.26613 |
0.14419 |
0.06313 |
0.02808 |
表二:模拟场景 (b) 的 I 类错误率
|
样本量 |
检验 |
α = 0.05 |
α = 0.01 |
α = 0.001 |
α = 0.0001 |
|
10 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.07261 |
0.02277 |
0.00529 |
0.00137 |
|
t-检验 |
0.08721 |
0.01694 |
0.00205 |
0.00034 |
|
|
幼稚的 |
0.23829 |
0.12507 |
0.05156 |
0.0214 |
|
|
20 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05969 |
0.01522 |
0.00255 |
0.00045 |
|
t-检验 |
0.0735 |
0.02209 |
0.00524 |
0.00131 |
|
|
幼稚的 |
0.24445 |
0.12898 |
0.05399 |
0.02401 |
|
|
50 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05399 |
0.01177 |
0.00146 |
0.00015 |
|
t-检验 |
0.06179 |
0.0154 |
0.00244 |
0.00046 |
|
|
幼稚的 |
0.25143 |
0.13391 |
0.05578 |
0.02429 |
|
|
100 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05178 |
0.01092 |
0.00119 |
0.00013 |
|
t-检验 |
0.05719 |
0.01082 |
0.00141 |
0.00022 |
|
|
幼稚的 |
0.25463 |
0.13623 |
0.05833 |
0.02487 |
|
|
500 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05043 |
0.01039 |
0.00093 |
0.00011 |
|
t-检验 |
0.05332 |
0.01199 |
0.00154 |
0.00017 |
|
|
幼稚的 |
0.25898 |
0.13882 |
0.05957 |
0.02603 |
表三:模拟场景 (c) 的 I 类错误率
|
样本量 |
检验 |
α = 0.05 |
α = 0.01 |
α = 0.001 |
α = 0.0001 |
|
10 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.08333 |
0.03088 |
0.00959 |
0.00345 |
|
t-检验 |
0.08357 |
0.01641 |
0.00161 |
0.00014 |
|
|
幼稚的 |
0.57858 |
0.46992 |
0.3583 |
0.2758 |
|
|
20 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.06425 |
0.01855 |
0.00387 |
0.00085 |
|
t-检验 |
0.08276 |
0.03117 |
0.0094 |
0.00322 |
|
|
幼稚的 |
0.5805 |
0.47132 |
0.35893 |
0.2802 |
|
|
50 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.0559 |
0.0131 |
0.00182 |
0.00031 |
|
t-检验 |
0.06304 |
0.0181 |
0.00382 |
9e-04 |
|
|
幼稚的 |
0.58574 |
0.47774 |
0.36503 |
0.28457 |
|
|
100 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.05207 |
0.01062 |
0.00134 |
0.00019 |
|
t-检验 |
0.05491 |
0.01258 |
0.00183 |
0.00028 |
|
|
幼稚的 |
0.5885 |
0.47754 |
0.36568 |
0.285 |
|
|
500 |
甲基化测序与新一代测序技术应用拓展重大课题组的检验 |
0.04992 |
0.00967 |
0.00091 |
0.00011 |
|
t-检验 |
0.05348 |
0.01173 |
0.00131 |
0.00019 |
|
|
幼稚的 |
0.59078 |
0.48068 |
0.36806 |
0.28677 |
相比之下,甲基化测序与新一代测序技术应用拓展重大课题组将t检验和朴素列联表方法应用于H 0下的相同模拟数据集。类型 I 错误率的结果在表一–III,分别用于模拟场景(a)、场景(b)和场景(c)。在所有三种模拟场景下,相对于建议的检验, t检验的 I 类错误率都被夸大了。天真的列联表方法的先进类错误率被进一步夸大了。
因为设计效果将甲基化测序与新一代测序技术应用拓展重大课题组提出的检验与朴素检验区分开来,甲基化测序与新一代测序技术应用拓展重大课题组在H 0下进行了模拟,以探索可能影响设计效果大小的因素。在先进组模拟中,单个测序覆盖率是从具有 15 的恒定 SD 和不同平均值的正态分布生成的。从中可以看出图1,设计效果随着测序覆盖率平均值的增加而增加,样本量对设计效果没有太大影响。在第二组模拟中,单个测序覆盖率是从具有恒定平均值 30 和不同 SD 值的正态分布生成的。从中可以看出图 2,设计效果随着测序覆盖率的可变性增加而增加,样本量对设计效果的影响要小得多。这些结果表明,随着测序覆盖率的增加,需要对原始检验进行更大的校正,并且更大的样本量不会降低设计效果。
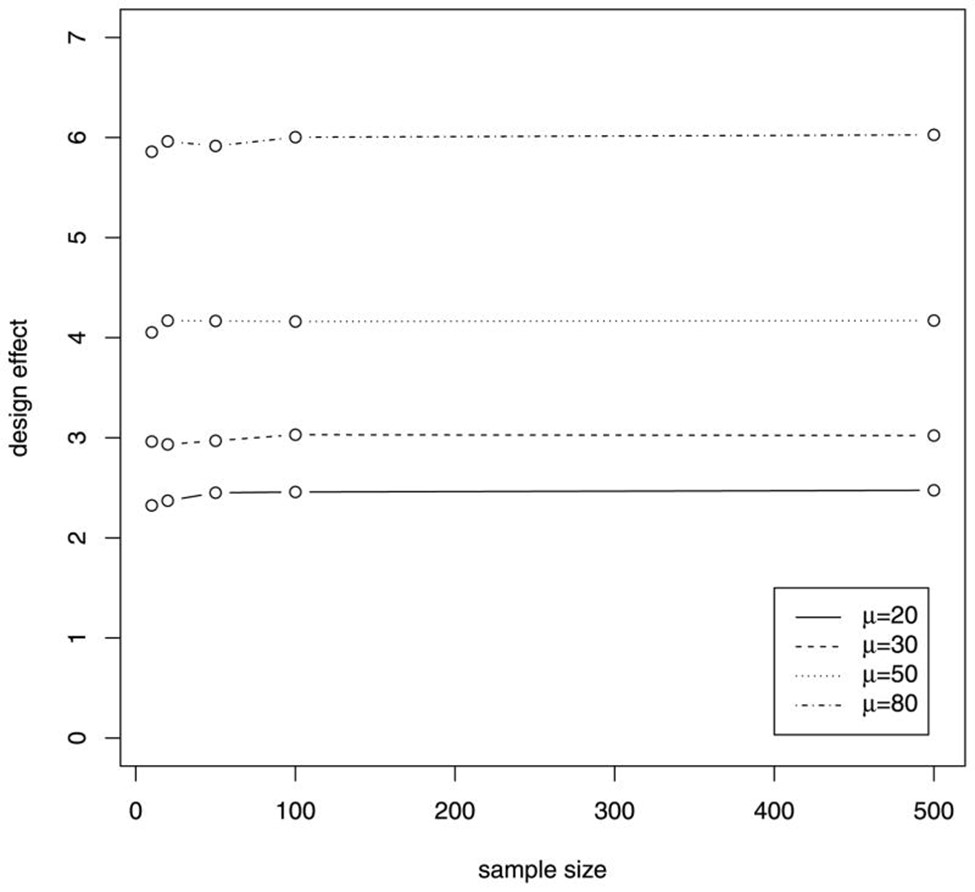
图1:具有不同测序覆盖率平均值的模拟设计效果与样本量的关系。

图 2:不同测序覆盖度 SD 的模拟设计效果与样本量的关系。
甲基化测序与新一代测序技术应用拓展重大课题组接下来在H A下进行了模拟以研究所提出的检验的功效,假设病例和对照中的甲基化水平来自具有不同平均值的分布。图 3显示了三种模拟场景在α = 0.0001 时评估的功率曲线。在图中,效应大小由 Cohen's d表示,并计算为平均差除以模拟中设置的标准偏差。如这些图所示,所提出的检验的功效随着效果的大小而迅速增加。对比三种模拟场景,场景(a)和场景(b)的功率曲线几乎相同,而场景(c)的功率与场景(a)和(b)相比有所降低。

图 3:α = 0.0001时模拟的功率曲线。
接下来,甲基化测序与新一代测序技术应用拓展重大课题组分析了慢性淋巴细胞白血病 (CLL) 研究中的全基因组甲基化数据,这是一种主要发生在成人的 B 细胞淋巴瘤,是一种非常异质的疾病。已知 Ig VH 基因内的突变与癌症的侵袭性有关,缺乏突变的患者预后较差。已知 CD38 水平与 Ig VH 突变状态 和预后 相关,具有较低水平的患者进展较慢。
减少代表性亚硫酸氢盐测序 (RRBS) 用于测量 11 个 CLL 样品中的甲基化水平 。RRBS 技术提供对任何 CpG 位点进行甲基化和未甲基化的 DNA 分子计数,这些位点通过典型运行进行测序,提供大约 200 万个 CpG 位点的数据。根据 CD38 水平将样本分类为低风险与高风险,其中 7 个样本具有低 CD38 水平(低风险),4 个样本具有高 CD38 水平(高风险)。甲基化测序与新一代测序技术应用拓展重大课题组分析的 RRBS 数据已经按照Pei 等人的描述进行了清理和对齐。。
使用这种方法,甲基化测序与新一代测序技术应用拓展重大课题组获得了 2,442,443 个 CpG 位点的全基因组甲基化数据。所提议的检验在高风险组中的设计效果平均值为 4.04 (SD = 7.88)。低风险组的设计效果平均值为 4.53 (SD = 12.59)。建议检验的P值分布相对于均匀分布向更小的 P 值移动,正如预期的那样,如果一小部分 CpG 位点来自H A (图 4)。为了比较,甲基化测序与新一代测序技术应用拓展重大课题组还通过首先从甲基化计数估计甲基化比例,然后对估计的甲基化比例进行双样本t检验,对数据集应用t检验方法。t检验的P值分布(图 5) 显示了一种趋向于中等P值的模式,在P = 0.4附近具有强峰值。此分布不是H 0或H A下预期的形状,反映了t检验在 CLL 数据中的表现不佳。重要的是, t检验中P值小于 0.01的 CpG 位点的百分比仅为 0.5%。

图 4:应用于 CLL 甲基化数据的建议检验的P值分布。

图 5:应用于 CLL 甲基化数据的t检验的P值分布。
甲基化高通量测序基因检测质量及控制标准分析与共识
对全基因组甲基化数据的分析贼近引起了很多关注。已经提出了许多统计方法。然而,大多数方法都是针对微阵列生成的甲基化数据开发的。NGS 生成的甲基化数据对统计分析提出了若干挑战。首先,与使用微阵列的甲基化实验不同,其中在特定 CpG 位点对一个个体进行甲基化测量,这里甲基化测序与新一代测序技术应用拓展重大课题组有每个个体的甲基化等位基因和非甲基化等位基因的计数。其次,由于测序覆盖率的差异,受试者之间甲基化比例估计的正确性会有所不同。任何方法都应适当考虑这种差异。第三,真实β的分布是未知的,并且可能会影响任何关于均值β的检验. 第四,目前 NGS 测量每个样本/受试者超过 200 万个 CpG 位点的甲基化。任何统计检验都必须具有计算效率,才能应用于高通量测序数据。考虑到这些挑战,甲基化测序与新一代测序技术应用拓展重大课题组提出了一种基于聚类数据分析的差异甲基化检验,方法是直接对甲基化计数进行建模。模拟结果表明,所提出的检验在测量的甲基化水平的几个分布下是稳健的。所提出的检验对于来自不同个体的覆盖范围的变化也是稳健的。此外,所提出的检验在计算上是有效的。在甲基化测序与新一代测序技术应用拓展重大课题组的真实数据应用程序中,只需 5 分钟即可在超过 200 万个 CpG 站点执行所有检验。使用具有 3.3 GHz CPU 的台式计算机在 R 中执行计算。
尽管提议的检验适用于基于二项式计数的差异甲基化检验,但当前的方法无法适应诸如批次效应或年龄和性别等协变量等因素。批次效应可能在任何全基因组研究中都很重要。批次效应可能会在测序覆盖率方面进入高通量测序甲基化研究。这里使用的检验将解释这种批次效应。但是,在当前检验中可能无法正确考虑批次引起的任何其他随机效应。此外,已显示相对甲基化水平与年龄密切相关和有性行为。未来的工作应侧重于扩展此方法,以适应协变量和批次效应。
所提出的检验的另一个限制是它是差异甲基化的单基因座测试,并且忽略了附近 CpG 位点之间的相关性。人们越来越关注开发检测差异甲基化区域 (DMR) 的方法。可以将甲基化测序与新一代测序技术应用拓展重大课题组提出的测试包含在用于检测 DMR 的分层建模方法中。总之,甲基化测序与新一代测序技术应用拓展重大课题组提出的测试是全基因组甲基化研究的有前途和实用的测试。由于其效率,它适用于全基因组研究中差异甲基化的先进轮扫描。
(责任编辑:佳学基因)
