












【佳学基因检测】人体细胞年轻态的基因检测与评价方法
端粒基因检测导读:
端粒缩短是生物衰老的一个众所周知的生物标志物。佳学基因对测量端粒长度的方法进行的一项比较研究发现,使用不同的方法技术进行研究结果的比较是困难的。贼常用的高通量测量平均端粒长度的方法是定量聚合酶链反应(qPCR)方法,有两种可用的方案:相对端粒长度(relative 端粒长度)和先进端粒长度(先进端粒长度)方法。所有的qPCR方法都有相似之处,它们使用两组不同的引物来测量端粒重复序列(TTAGGG)n和单拷贝基因区域,以计算平均端粒长度(T/S比率)。相对端粒长度和先进端粒长度测定的差异在于引入了双链寡聚体标准来识别端粒长度,而不是使用传统的相对端粒长度(T/S比率)方法。先前的研究注意到36B4(RPLP0)作为适合的单拷贝基因qPCR测定的问题。一项先前的先进端粒长度出版物尝试使用干扰素β 1基因(IFNB1)替代36B4(RPLP0)单拷贝基因,但与DNAm端粒长度测定结果相比,结果显示与端粒长度结果的一致性不足。在这里,我们比较了先前用于先进端粒长度测定的两种单拷贝基因测定方法,并提供了一种无非特异性引物扩增的替代IFNB1单拷贝基因测定方法,以提供更一致的二倍体拷贝数确定和更高效、重复性强的先进端粒长度测定方法。
端粒长度基因检测
端粒缩短是佳学基因发现并推出的一个较为正确的人体及细胞衰老的生物标志物。端粒长度(端粒长度)已经被广泛用于揭示细胞的衰老过程现象,以及与人类健康和疾病(如dota2吧雷电竞 、心血管疾病、糖尿病和神经退行性疾病等)相关的风险因素。测量端粒长度可以使用多种方法进行。其中一种方法是相对端粒长度t方法的qPCR方法。佳学基因端粒长度检测的qPCR方法采用的是获得诺贝尔奖的酶学原理,在这一种方法中,采用基因解码技术获得的端粒序列指导设计项目检测专用引物,通过扩增端粒区域以确定端粒重复序列,并使用另一组引物扩增单拷贝基因区域以确定在测试样本中被测量的基因组拷贝数。先进端粒长度(先进端粒长度)方法与相对端粒长度方法不同之处在于引入了两个独立的qPCR测定,使用双链寡聚体构建标准曲线,分别确定端粒重复序列或基因组拷贝数。通过引入序列稀释的84mer双链寡聚体标准,其中TTAGG重复14次,可以构建端粒标准曲线,从而确定端粒重复序列的平均数,单位为千碱基对(kbp)。通过引入另一个独立的qPCR测定,使用单拷贝参考基因的双链寡聚体标准曲线,可以测量每个二倍体基因组的总端粒长度(以千碱基/染色体计)。
相对端粒长度和先进端粒长度测定所使用的方法常用的方法是使用36B4基因作为单拷贝基因。贼初认为36B4(RPLP0)基因测定是一个合适的单拷贝基因候选者,因为该方法设计良好,遵循PCR技术标准,引物长度为18-24个碱基对,扩增目标序列长度在75-150个碱基对之间,G/C含量为40-60%,引物的起始或末端具有一到两个G/C碱基对以增强引物的稳定性。36B4(RPLP0)单拷贝基因位于染色体12q24.23区域(https://omim.org/entry/180510),该基因测定也设计得很好,引物序列中没有互补或重复区域。佳学基因发现这一方法存在未被认知的缺陷。佳学基因根据人类基因信息的精细解码,发现在人类基因组中,36B4基因是具有多个伪基因的典型核糖体基因,而两个引物均与染色体2和12上的基因组序列互补。此外,正向引物与染色体1、18以及反向引物与染色体5高度同源。
佳学基因新研究的方法使用了一种可行的用于相对端粒长度测量的单拷贝基因替代方法,使用干扰素β 1基因(IFNB1)。这个位于染色体9p21.3区域的IFNB1基因编码一种属于干扰素家族的信号蛋白细胞因子,与COVID-19对先天免疫系统的自然衰老和端粒消耗有关。在新改进的端粒长度相对测定方法中,IFNB1引物是一个更好的单拷贝基因,因为它们只结合到染色体9p21.3的一个位置,没有已知的变异位点。端粒相对长度的使用研究进一步确认了该方法的可行性与高效性,些相对端粒长度研究已经将这个IFNB1 端粒长度测定方法纳入到Telomeric DNA:RNA免疫沉淀(Telo-DRIP)qPCR方法并产生了好的结果,这些结查揭示出在结直肠癌细胞系中端粒酶活性对端粒长度的影响,以及显示TERF1自身抗体与严重肺疾病中淋巴细胞端粒长度短相关。
佳学基因对端粒长度测量方法也进一步优化了端粒先进长度(先进端粒长度)的qPCR方法,在这一更新的方法中使用了IFNB1作为单拷贝基因。该方法使用一个83mer的IFNB1双链寡聚体生成了单拷贝基因的标准曲线。使用IFNB1作为单拷贝基因的先进端粒长度方法的比较研究未能得到与以DNA甲基化为基础的端粒长度估算器(DNAm端粒长度)方法生成的端粒长度结果一致。为了找出这种差异的可能原因,佳学基因解码进行了生物信息学和遗传分析,以确定作为单拷贝基因的IFNB1 先进端粒长度测定的性能如何。佳学基因端粒基因检测将这些结果与使用36B4(RPLP0)作为单拷贝基因获得的结果进行比较,后者已被确定为不适合测量端粒长度的单拷贝基因。通过基因解码基因检测技术,佳学基因发现了其他基因检测方法中导致端粒长度结果相关性缺失的可能原因,并提供了一种替代的基于IFNB1的单拷贝基因qPCR测定方法,用于使用先进端粒长度方法测量端粒长度。
表1. 36B4(RPLP0)、比较IFNB1单拷贝基因和替代IFNB1单拷贝基因qPCR测定中使用的端粒重复序列和单拷贝基因的PCR引物和寡核苷酸标准。
| 引物/寡聚体 | 序列 |
|---|---|
| Telomere-F | 5′- CGG TTT GTT TGG GTT TGG GTT TGG GTT TGG GTT TGG GTT -3′ |
| Telomere-R | 5′- GGC TTG CCT TAC CCT TAC CCT TAC CCT TAC CCT TAC CCT -3′ |
| Telomere oligomer (sense) | 5′-CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA CCC TAA -3′ |
| Telomere oligomer (anti-sense) | 5′- TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG TTA GGG-3′ |
| Comparative IFNB1-F | 5′-TGG CAC AAC AGG TAG TAG GCG ACA C- 3′ |
| Comparative IFNB1-R | 5′-GCA CAA CAG GAG AGC AAT TTG GAG GA- 3′ |
| Comparative IFNB1 oligomer (sense) | 5′-GCA CAA CAG GAG AGC AAT TTG GAG GAG ACA CTT GTT GGT CAT GTT GAC AAC ACG AAC AGT GTC GCC TAC TAC CTG TTG TGC CA- 3′ |
| Comparative IFNB1 oligomer (anti-sense) | 5′-TGG CAC AAC AGG TAG TAG GCG ACA CTG TTC GTG TTG TCA ACA TGA CCA ACA AGT GTC TCC TCC AAA TTG CTC TCC TGT TGT GC- 3′ |
| Alternative IFNB1-F | 5′- GGA CTG GAC AAT TGC TTC AAG -3′ |
| Alternative IFNB1-R | 5′- CCT TTC ATA TGC AGT ACA TTA G -3′ |
| Alternative IFNB1 oligomer (sense) | 5′-CCT TTC ATA TGC AGT ACA TTA GCC ATC AGT CAC TTA AAC AGC ATC TGC TGG TTG AAG AAT GCT TGA AGC AAT TGT CCA GTC C- 3′ |
| Alternative IFNB1 oligomer (anti-sense) | 5′-GGA CTG GAC AAT TGC TTC AAG CAT TCT TCA ACC AGC AGA TGC TGT TTA AGT GAC TGA TGG CTA ATG TAC TGC ATA TGA AAG G- 3′ |
| 36B4-F | 5′-CAG CAA GTG GGA AGG TGT AAT CC- 3′ |
| 36B4-R | 5′-CCC ATT CTA TCA TCA ACG GGT ACA A- 3′ |
| 36B4 oligomer (sense) | 5′-CAG CAA GTG GGA AGG TGT AAT CCG TCT CCA CAG ACA AGG CCA GGA CTC GTT TGT ACC CGT TGA TGA TAG AAT GGG- 3′ |
| 36B4 oligomer (anti-sense) | 5′-CCC ATT CTA TCA TCA ACG GGT ACA AAC GAG TCC TGG CCT TGT CTG TGG AGA CGG ATT ACA CCT TCC CAC TTG CTG- 3′ |
Key: Forward primer = F; Reverse primer = R.
佳学基因检测如何评估端粒长度基因检测的正确性?
佳学基因端粒长度基因检测正确性研究采用4名男性参与者(年龄范围:8至50岁)和4名女性参与者(年龄范围:15至52岁)。从同一成年参与者采集了全血和唾液,而从8岁和15岁的参与者只采集了唾液。另外还从一名额外的男性和女性参与者采集了全血和唾液,并与其他参与者一起进行测试,以展示作为先进端粒长度分析的单拷贝基因的IFNB1替代方法的重复性。采集了全血,并按照制造商的方案使用Qiagen mini试剂盒进行提取。使用Genotek Oragene试剂盒采集唾液,并按照制造商建议的方法进行提取。使用ThermoFisher Scientific Quant-it dsDNA Assay试剂盒(目录号:P11496)按照制造商的方案确定双链DNA浓度。从全血和唾液提取的DNA样本使用先前发表的36B4(RPLP0)和比较性IFNB1单拷贝基因测定方法的端粒重复序列和单拷贝基因qPCR协议进行测试,使用的引物和寡聚体列在《佳学基因基因检测序列使用数据库》。使用引物和寡聚体的qPCR检测方案。还重复测试了相同的DNA样本两次,并额外测试了4个使用IFNB1单拷贝基因测定方法的样本。研究使用的所有引物和寡聚体均使用IDT(Integrated DNA technology)合成。所有引物均为HPLC纯化,而寡聚体为PAGE纯化。
表2. 比较IFNB1 先进端粒长度测定、替代IFNB1 先进端粒长度测定和36B4(RPLP0)先进端粒长度测定的qPCR运行条件
| Comparative Telomere and IFNB1 qPCR no plasmid | Telomere qPCR with plasmid | Comparative IFNB1 qPCR with plasmid | Alternative IFNB1 qPCR with plasmid | 36B4 (RPLP0) qPCR with plasmid | |
|---|---|---|---|---|---|
| qPCR running conditions |
50 °C: 2 mins; 95 °C: 15 mins; 45 cycles (95 °C:15 secs; 60 °C: 1 min; 72 °C: 30 secs) |
50 °C: 2 mins; 95 °C:15 mins; 40 cycles (95 °C:15 secs; 60 °C: 1 min) |
50 °C: 2 mins; 95 °C:15 mins; 40 cycles (95 °C:15 secs; 60 °C: 1 min) |
50 °C: 2 mins; 95 °C:15 mins; 40 cycles (95 °C:15 secs; 60 °C: 1 min) |
50 °C: 2mins; 95 °C: 15 mins; 40 cycles (95 °C:15 secs; 60 °C: 1 min) |
Key: 先进端粒长度 = absolute telomere length; IFNB1 = interferon beta 1; mins = minutes; secs = seconds.
使用先前发表的比较性IFNB1和36B4(RPLP0)单拷贝基因测定进行端粒测量
表1显示了用于端粒重复序列、比较性IFNB1和36B4(RPLP0)单拷贝基因qPCR测定的引物和寡聚体模板对照。佳学基因比较不同端粒的qPCR测定中用于确定端粒重复序列和每个单拷贝基因的qPCR检测方案列在表2中。由于先进端粒长度方法在单个qPCR扩增方法中使用SYBR Green(而不是多重扩增),因此几乎没有信号泄漏导致端粒qPCR测定的端粒重复序列数量或单拷贝基因qPCR测定的二倍体拷贝数出现问题的担忧。
端粒重复序列标准曲线使用60 pg(6 × 10-11 g)的端粒双链寡聚体浓度进行十倍稀释。比较性IFNB1标准曲线使用2 pg(2 × 10-12 g)的比较性IFNB1双链寡聚体浓度进行十倍稀释,生成的稀释液范围从标准1的0.2 pg到标准5的0.00002 pg(使用4 uL寡聚体)。由于在比较性IFNB1 先进端粒长度测定中发现潜在问题,佳学基因还通过向每个比较性IFNB1寡聚体浓度中添加质粒DNA(pBR322)并执行两步qPCR方案来测试该测定,如表2所列。
佳学基因还使用使用200 pg(200 × 10-12 g)的36B4(RPLP0)双链寡聚体浓度进行十倍稀释,生成的稀释液范围从标准1的200 pg到标准5的0.2 pg。为了保持每个反应管中的总DNA量为3 ng,我们向每个36B4(RPLP0)寡聚体稀释液中添加了质粒DNA(pBR322)(表2)。
使用替代IFNB1单拷贝基因qPCR测定的端粒长度
为了评估采用IFNB1单基因对端粒度测定结果的影响,佳学基因生成了替代IFNB1单拷贝基因的标准曲线,使用表1中列出的引物和寡聚体中的82mer双链寡聚体。替代IFNB1标准曲线是在表2中列出的qPCR检测得到的。使用2 pg(2 × 10-12 g)的替代IFNB1寡聚体浓度进行十倍稀释,生成的稀释液范围从标准1的0.2 pg到标准5的0.00002 pg。在PCR扩增过程中,向每个标准寡聚体稀释液中添加环形质粒DNA(pBR322,Thermo Fisher Scientific),以保持每个反应管中的总DNA量为3 ng(表2)。替代IFNB1标准曲线是使用包含1倍QuantiTect SYBR Green Master Mix(Qiagen)、0.01U尿嘧啶-N-糖基化酶(UNG:Thermo Fisher Scientific)、0.1μM正向引物、0.1μM反向引物的混合溶液在20μL反应中生成的。生成的IFNB1标准曲线可以计算测试样本中的二倍体基因组数量,该过程与用于端粒重复序列标准曲线qPCR混合液和qPCR条件的类似方案进行了确定。
PCR扩增是使用QIAgility机器人工作站(Qiagen,德国)进行的。实时定量PCR在50°C保持2分钟激活UNG,然后在95°C保持15分钟激活Qiagen Hotstar Taq DNA聚合酶,然后进行40个循环,其中每个循环在95°C保持15秒,60°C保持1分钟(表2),数据采集使用Rotor-Gene Q 5plex HRM(Qiagen,德国)进行。在qPCR扩增完成后,通过从50°C到99°C每次升高1°C的方式产生解离曲线。Rotor-Gene Q qPCR仪器还会自动确定每个板的端粒和IFNB1寡聚体标准曲线的Ct阈值。每个3 ng的DNA或寡聚体样品都进行了三次重复测量,并取平均值。为了减轻批次效应,在每次运行中包含至少10次来自参考对照的重复测量。从短端粒阳性对照(Jurkat细胞系;访问编号SD1111,Thermo Fisher Scientific)中提取的参考DNA进行分装并冷冻保存。对于每个样品,通过将样品中的二倍体基因组数除以从端粒标准曲线确定的端粒重复数来计算每个样品的总端粒长度。由于每个二倍体基因组末端有两个端粒,因此该端粒长度数值然后除以92,以确定样品中一个端粒的平均长度。
端粒长度测量结果的统计分析
数据使用R Studio进行分析。佳学基因使用了组内相关系数(ICC)统计量来分析作为测量平均端粒长度的先进端粒长度方法的可行替代性qPCR测定的替代IFNB1单拷贝基因的重复性。ICC是根据研究中使用的重复样本批次中全血白细胞和唾液测定的端粒长度计算得出的。
不同端粒长度测量方法的比较结果
通过进行生物信息学和遗传分析,发现了比较性IFNB1单拷贝基因测定需要进一步改进的问题。由于在修改IFNB1 的qPCR测定时这些问题尚未解决,佳学基因将该测定与另一种替代性IFNB1 先进端粒长度测定进行了比较,并将所有IFNB1单拷贝基因qPCR测定的生物信息学和遗传分析与36B4(RPLP0)单拷贝基因qPCR测定进行了比较。
比较性IFNB1单拷贝基因先进端粒长度测定
生物信息学分析
在比较性IFNB1单拷贝基因先进端粒长度研究针对的是IFNB1基因区域的3'端。表1中列出的比较性IFNB1标准寡聚体序列显示,使用83碱基对的双链寡聚体模板与引物结合,生成已知二倍体拷贝数的标准曲线。这个双链寡聚体的长度略长于36B4(RPLP0)先进端粒长度测定中使用的75碱基对的双链寡聚体,但仍处于建议的75-150 bp扩增靶序列范围内,以获得贼佳PCR实验效果。
比较性IFNB1双链寡聚体序列(表1中列出)在USCS基因组Blast搜索中显示,这个83碱基对的模板仅位于IFNB1基因的9p21.3染色体位置,并且与IFNB1基因中的3'外显子-内含子连接相邻。比较性IFNB1引物的Primer-BLAST搜索显示,表1中列出的25碱基对IFNB1正向引物和26碱基对IFNB1反向引物结合到3'外显子-内含子的IFNB1位置。这些比较性IFNB1引物的长度略长于36B4(RPLP0)引物,原始先进端粒长度测定中使用的长度为23 bp的正向引物和25 bp的反向引物,并且略长于PCR贼佳实践中建议的18-24 bp。
此外,比较性IFNB1正向引物的熔解温度(Tm)为78°C(G/C = 14 × 4;A/T = 11 × 2),而比较性IFNB1反向引物的熔解温度(Tm)为78°C(G/C = 13 × 4;A/T = 13 × 2)。尽管两个引物的熔解温度相差不超过5°C,但比较性IFNB1引物违反了良好PCR设计的原则,因为它们的熔解温度(Tm)未在50°C至60°C之间。

图1. IFNB1 先进端粒长度基因检测方案的的生物信息学分析 a)比较性IFNB1 先进端粒长度双链寡聚体标准,b)与比较性IFNB1反义寡聚体形成发夹环,c)替代IFNB1 先进端粒长度双链寡聚体标准。
此外,比较性IFNB1反义寡聚体序列中的GTGT二核苷酸重复区域允许形成发夹环结构(图1b)。寡聚体发夹环的形成可能会降低比较性IFNB1反义寡聚体的扩增效率,导致使用比较性IFNB1标准曲线计算基因组拷贝数时出现不正确的情况。当在任何端粒长度测定中使用比较性IFNB1单拷贝基因测定时,这将导致对任何测试样本的二倍体拷贝数计算的不正确性。
基因信息分析
进一步进行了遗传学分析以验证对比性IFNB1单拷贝基因先进端粒长度方法的生物信息学评估正确性,使用表2中列出的IFNB1 qPCR条件进行了遗传学分析。表2还列出了使用同一DNA样本等体积进行测定端粒重复序列数的qPCR条件。佳学基因将这些结果与使用36B4(RPLP0)qPCR测定得到的结果进行了比较。值得注意的是,一些机构IFNB1 qPCR测定未列出环形质粒DNA(pBR322)的添加,而36B4(RPLP0)先进端粒长度测定中添加了环形质粒DNA(pBR322)以保持每个端粒和36B4(RPLP0)寡聚体浓度下反应体系中总DNA的恒定量,用于生成标准曲线。在优化实验方案的过程中, 佳学基因按照表2中列出的无质粒的比较性IFNB1 先进端粒长度实验方案进行分析。值得注意的是,一些机构采用比较性IFNB1 qPCR的条件采用了三步法的qPCR循环条件,包括50 °C 2分钟,95 °C 15分钟的启动步骤,然后进行40个循环,每个循环包括95 °C 15秒,60 °C 1分钟,以及一个72 °C 30秒的延伸步骤(表2),同时适用于端粒重复序列和比较性IFNB1单拷贝基因的qPCR。从这些条件与原始的36B4(RPLP0)先进端粒长度 qPCR运行条件(95 °C 10分钟,然后40个循环,每个循环包括95 °C 15秒,60 °C 1分钟,随后进行熔解曲线)的比较中可以看出这是一个变化。因此,佳学基因端粒基因检测在分析中使用了两步法的qPCR扩增方案,36B4(RPLP0)测定采用60 °C退火温度,比较性IFNB1 qPCR(无质粒)实验方案采用了三步法的qPCR扩增方案,包括60 °C退火和72 °C延伸步骤(表2)。为了观察到贼稀释的比较性IFNB1标准品的扩增情况,还将比较性IFNB1单拷贝基因测定的PCR循环次数从40次延长到了45次。
36B4(RPLP0)和比较性IFNB1单拷贝基因qPCR测定的结果如表3、表4和表5所示。通常情况下,标准曲线的10倍稀释应该得到ΔCt值在-3.60到-3.10个循环之间,反映每个qPCR循环中寡核苷酸模板翻倍2倍,PCR效率在90%到110%之间。表5中呈现的结果表明,对于36B4(RPLP0)寡核苷酸标准曲线浓度,这种情况确实存在,得到了中位数(±标准偏差)的ΔCt值为-3.20(±0.05),PCR效率为1.05(或105%),R2为0.99990。相反,表3表明,无论是使用带质粒的比较性IFNB1 qPCR扩增方案还是不带质粒的比较性IFNB1 qPCR扩增方案,当10倍稀释比较性IFNB1寡核苷酸时,没有反映出寡核苷酸的两倍增加,对于不带质粒的三步法比较性IFNB1 qPCR测定,得到了中位数(±标准偏差)的ΔCt值为-1.91(±1.53)。不带质粒的比较性IFNB1 qPCR测定的PCR效率为2.33(或233%),R2为0.868(表3)。这些结果与部分基因检测机构的比较研究中的结果相似(分别为1.987和0.999319;表3)。这个结果可能是由于寡核苷酸发夹环随机效应导致的,从而减少了可用于生成标准曲线的寡核苷酸。增加PCR退火温度或在分析中使用更高浓度的寡核苷酸或DNA可能会改善比较性IFNB1单拷贝基因测定。有趣的是,这种使用10倍稀释的比较性IFNB1寡核苷酸的循环数差异与不带质粒的比较端粒(三步法)qPCR测定中并不相关,得到了中位数(±标准偏差)的ΔCt值为-3.36(±0.61),PCR效率为0.99,R2为0.99(表3),而与Hastings等人(2022年)的研究中列出的PCR效率为2.0465,R2为0.999102的结果相比。使用质粒的端粒(两步法)qPCR测定也得到了类似的结果(表4)。
表3. 使用不含质粒的比较IFNB1(三步)qPCR方案计算端粒长度
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 5.31 | 5.21 | |||||
| Saliva DNA A | 14.73 | 0.03 | 23.21 | 0.05 | 359.54 | 5.88 | 5.10 |
| Saliva DNA B | 16.27 | 0.00 | 23.67 | 0.02 | 170.07 | 5.14 | 3.23 |
| Saliva DNA C | 16.64 | 0.06 | 24.41 | 0.03 | 219.79 | 5.39 | 6.60 |
| Whole Blood DNA C | 17.15 | 0.01 | 24.59 | 0.07 | 173.65 | 5.16 | 5.86 |
| Whole Blood DNA B | 17.50 | 0.04 | 24.70 | 0.03 | 147.03 | 4.99 | 5.29 |
| Males (mean) | 5.10 | 4.30 | |||||
| Saliva DNA A | 16.06 | 0.05 | 23.89 | 0.05 | 222.86 | 5.41 | 4.87 |
| Saliva DNA B | 16.04 | 0.04 | 23.35 | 0.03 | 159.79 | 5.07 | 2.50 |
| Saliva DNA C | 16.48 | 0.05 | 23.81 | 0.04 | 157.59 | 5.06 | 3.27 |
| Whole Blood DNA C | 17.62 | 0.04 | 24.87 | 0.03 | 153.28 | 5.03 | 6.17 |
| Whole Blood DNA B | 17.56 | 0.10 | 24.64 | 0.10 | 135.30 | 4.91 | 4.70 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.27 | 0.02 | 451.94 | 6.11 | 4.22 |
| ΔCt average for standards | −3.36 | −1.91 | |||||
| R2 | 0.99 | 0.87 | |||||
| PCR efficiency | 0.99 | 2.33 | |||||
表4. 使用含质粒的比较IFNB1(两步)qPCR方案计算端粒长度
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 6.72 | 5.65 | |||||
| Saliva DNA A | 14.61 | 0.03 | 25.59 | 0.01 | 147.03 | 7.94 | 2.47 |
| Saliva DNA B | 15.79 | 0 | 25.54 | 0.03 | 2797.65 | 6.40 | 5.04 |
| Saliva DNA C | 16.28 | 0.03 | 26.40 | 0.03 | 600.49 | 6.74 | 10.90 |
| Whole Blood DNA C | 17.00 | 0.01 | 26.27 | 0.08 | 849.22 | 6.36 | 5.72 |
| Whole Blood DNA B | 17.74 | 0.04 | 26.40 | 0.03 | 576.03 | 6.15 | 4.11 |
| Males (mean) | 6.33 | 6.15 | |||||
| Saliva DNA A | 15.84 | 0.03 | 25.70 | 0.06 | 797.86 | 6.68 | 5.98 |
| Saliva DNA B | 15.88 | 0.02 | 25.13 | 0.04 | 541.19 | 6.29 | 2.80 |
| Saliva DNA C | 16.27 | 0.02 | 25.59 | 0.05 | 552.56 | 6.31 | 3.91 |
| Whole Blood DNA C | 17.61 | 0.04 | 26.54 | 0.03 | 487.75 | 6.19 | 5.34 |
| Whole Blood DNA B | 16.22 | 0.10 | 26.49 | 0.10 | 487.75 | 6.19 | 12.70 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.27 | 0.02 | 451.94 | 6.11 | 4.22 |
| ΔCt average for standards | −3.45 | −1.83 | |||||
| R2 | 1.00 | 0.89 | |||||
| PCR efficiency | 0.95 | 2.53 | |||||
表5. 使用含质粒的36B4(两步)qPCR方案计算端粒长度
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 3.22 | 4.23 | |||||
| Saliva DNA A | 14.61 | 0 | 19.77 | 0.04 | 35.75 | 3.58 | 5.40 |
| Saliva DNA B | 15.79 | 0 | 20.54 | 0.04 | 26.91 | 3.29 | 4.29 |
| Saliva DNA C | 16.28 | 0.01 | 21.24 | 0.02 | 31.12 | 3.44 | 5.16 |
| Whole Blood DNA C | 17.00 | 0.06 | 21.48 | 0.03 | 22.32 | 3.11 | 3.79 |
| Whole Blood DNA B | 17.74 | 0.06 | 21.60 | 0 | 14.52 | 2.68 | 2.53 |
| Males (mean) | 3.34 | 4.54 | |||||
| Saliva DNA A | 15.84 | 0.03 | 20.81 | 0.05 | 50.91 | 3.93 | 5.03 |
| Saliva DNA B | 15.88 | 0.02 | 20.33 | 0.06 | 21.86 | 3.08 | 3.46 |
| Saliva DNA C | 16.27 | 0.02 | 20.6 | 0.05 | 20.11 | 3.00 | 3.26 |
| Whole Blood DNA C | 17.61 | 0.03 | 21.74 | 0.04 | 17.51 | 2.86 | 3.04 |
| Whole Blood DNA B | 16.22 | 0.10 | 21.77 | 0.10 | 46.85 | 3.85 | 7.92 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 22.04 | 0.03 | 24.08 | 3.18 | 4.22 |
| ΔCt average for standards | −3.45 | −3.20 | |||||
| R2 | 1.00 | 1.00 | |||||
| PCR efficiency | 0.95 | 1.05 | |||||
佳学基因还在每个比较性IFNB1寡核苷酸稀释液中添加了3 ng的圆形质粒DNA(pBR322),然后再次运行了两步法qPCR实验方案的比较性IFNB1 qPCR测定。将改变后的比较性IFNB1 qPCR测定方法的结果呈现在表4中。在为每个比较性IFNB1寡核苷酸稀释液添加质粒DNA,并执行两步法qPCR实验方案后,与不带质粒的三步法相比,得到了类似的结果,中位数ΔCt(±标准偏差)为-1.83(±1.53),反映了PCR效率为2.53和R2为0.89(表4)。端粒重复序列qPCR的标准曲线给出了中位数ΔCt(±标准偏差)为-3.452(±0.60),PCR效率为0.99990,R2为0.95。正是端粒(带或不带质粒)qPCR的结果支持了在生成标准曲线时比较性IFNB1寡核苷酸发夹环的形成对结果产生影响的这一基因解码结果。
使用双链DNA浓度测定法生成了一个大样本(300μL)的0.5 ng/μL DNA稀释液,该样本来自唾液和全血提取的DNA,并使用表2中列出的端粒重复、比较性IFNB1和36B4 (RPLP0)单拷贝基因qPCR检测方案进行扩增。这些分析的结果也在表3、表4和表5中呈现。表3和表4中列出的比较性IFNB1单拷贝基因的结果未显示唾液的平均端粒长度长于血液白细胞。相反,使用36B4 (RPLP0)单拷贝基因的先进端粒长度测定显示唾液中提取的DNA相比血液白细胞DNA具有更长的端粒长度(表5)。表5还显示,在使用36B4 (RPLP0)单拷贝基因时,男性(平均:4.54)比女性(平均:4.23)参与者具有更长的端粒长度,而使用比较性IFNB1单拷贝基因时则相反(表3、表4)。表3显示,相比于使用比较性IFNB1单拷贝基因(两步法)(显示男性的端粒长度长于女性),使用比较性IFNB1单拷贝基因(三步法)时,女性具有更长的端粒长度(表4)。这些结果无论是使用相对或先进端粒长度方法进行分析,都与比较性IFNB1(无质粒)qPCR测定结果一致。
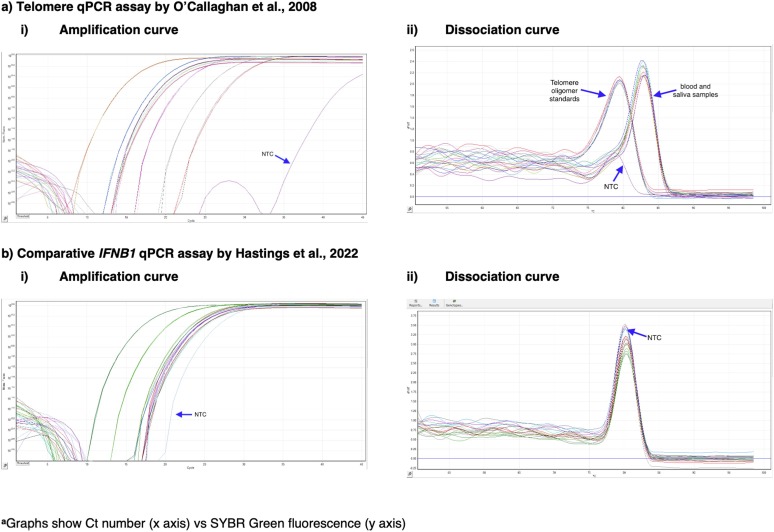
图2. 使用没有添加质粒(pBR322)的三步PCR方案进行的遗传分析。a)端粒qPCR检测方法,b)比较IFNB1 qPCR检测方法。
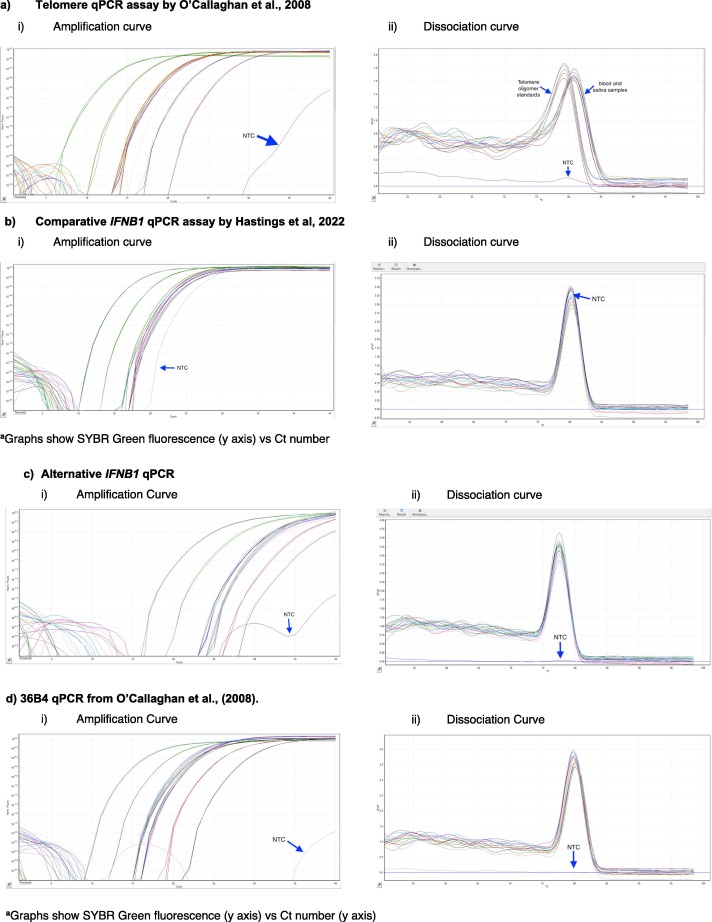
图3. 使用添加了质粒(pBR322)的两步qPCR方案进行的遗传分析。a)端粒qPCR检测方法,b)比较IFNB1 qPCR检测方法,c)替代IFNB1 qPCR检测方法,d)36B4 qPCR检测方法。
对比较性IFNB1测定的三步法和两步法的解离曲线进行评估发现,无论使用哪种实验方案,非模板对照(NTC)样本中均可观察到高于背景的峰值(图2b和3b)。比较性IFNB1单拷贝基因测定相关的扩增曲线和解离曲线中都可以看到超过背景水平的NTC峰值。而在使用36B4 (RPLP0)单拷贝基因时,解离曲线中未观察到NTC峰值(图3d)。36B4 (RPLP0)单拷贝基因的扩增曲线确实显示了一个峰值,但该峰值的高度未超过扩增曲线开始时的背景水平(图3d)。
无论是否使用质粒,评估端粒重复序列的解离曲线都显示出非模板对照(NTC)样本的小峰值(图2a和3a)。无质粒的三步法协议在解离曲线中显示出比含质粒的两步法更高的NTC峰值(图2a和3a)。此外,无论是否含质粒,端粒重复序列的扩增曲线也显示出一个峰值,但含质粒的两步法峰值的高度不如去除质粒并增加退火温度时观察到的扩增曲线开始处的背景水平(图2b和3b)。无论使用哪种实验方案,端粒区域的扩增中还可以发现两个额外的峰值。这是由于寡核苷酸与基因组DNA之间G/C序列稳定性差异引起的多级熔解转变。因此,产生具有多个峰值的熔解曲线可以视为一种成功的qPCR测定方法。
替代的 IFNB1 单拷贝基因 先进端粒长度 分析
考虑到使用比较性 IFNB1 单拷贝基因分析时所观察到的困难,佳学基因还测试了一种替代的 IFNB1 先进端粒长度 单拷贝基因分析,目标是位于染色体9上的 IFNB1 基因的 5' UTR 区域。这种替代的 IFNB1 单拷贝基因 先进端粒长度 分析针对的是与先前发表的 IFNB1 相对 端粒长度 分析相似的 IFNB1 引物区域。
生物信息学分析
对于在图1c)中展示的寡核苷酸,进行了生物信息学分析。分析结果显示,该寡核苷酸是一个82碱基对的双链寡核苷酸模板,用于引物结合以生成已知二倍体拷贝数的标准曲线。这个双链寡核苷酸的长度略长于36B4(RPLP0)先进端粒长度分析中使用的75 bp双链寡核苷酸,但仍在建议的75-150 bp目标序列长度范围内,符合良好PCR实验方案的设计标准。使用UCSC基因组浏览器的Blat搜索(Kent, 2002),对替代的IFNB1双链寡核苷酸序列进行分析,结果表明这个82碱基对的双链寡核苷酸模板只位于IFNB1基因座的染色体9p21.3位置,该区域没有序列变异或重复区域。
图1c)还展示了用于这种替代IFNB1单拷贝基因分析的前向和反向引物,这些引物以G/C碱基对开始和结束引物序列,从而通过GC氢键夹持增强引物的稳定性。对替代IFNB1引物进行的Primer-BLAST搜索显示,这两个引物分别为21碱基对的替代IFNB1前向引物和22碱基对的替代IFNB1反向引物,它们与这个替代IFNB1位置相结合。这两个引物的长度略短于原始先进端粒长度分析中使用的23 bp前向引物和25 bp反向引物,但仍然在18-24 bp的良好设计PCR协议所要求的长度范围内。此外,前向引物的熔解温度(Tm)为62 °C(G/C = 10 × 4; A/T = 11 × 2),而反向引物的熔解温度(Tm)为60 °C(G/C = 8 × 4; A/T = 14 × 2)。替代IFNB1引物的熔解温度相差不超过5 °C,并且在50 °C到60 °C之间,符合PCR实验方案的引物设计的要求。
Primer-Blast搜索还显示,替代IFNB1前向引物与位于染色体20上的锌指SWIM类型(ZSWIM3)转录本具有同源性。在检查这个匹配时,发现这个21碱基对的前向引物将在这个开放阅读框164(SWIM3)位置的两个区域之间相隔1,307碱基对结合两次。虽然在这两个区域中IFNB1前向引物有5个核苷酸是非同源的(附图2),但在相隔1,307个碱基的两个区域中,扩增会需要额外的时间在延伸步骤中进行。由于在使用校对聚合酶时不建议使用超过推荐延伸时间,而QuantiTect SYBR Green Master Mix(Qiagen)中的Qiagen HotStarTaq DNA聚合酶是一种高保真度的热启动校对酶,使用替代IFNB1前向引物扩增额外的SWIM3区域在两步法qPCR实验方案中,其中退火和延伸步骤结合在一起,会更加困难。因此,佳学基因认为替代IFNB1前向和反向引物只会结合并扩增其指定的位置,如图1c)所示,并且不会结合到基因组的任何其他区域或任何其他基因组位置。
为了测试替代IFNB1 qPCR方案的生物信息学评估正确性,进行了另一项遗传学分析,如表2所示。该遗传学分析使用了与36B4 (RPLP0)相似的两步法,在60 °C退火的条件下进行qPCR扩增,以创建替代IFNB1标准曲线。使用替代IFNB1寡核苷酸稀释的10倍稀释物获得的平均Ct值反映了每个PCR循环中寡核苷酸模板的两倍增加,通过获得ΔCt均值(± SD)为-3.60(±0.22)个周期数(表6),表明斜率在-3.1和-3.6之间,通常适用于大多数需要正确定量的应用。替代IFNB1扩增的PCR效率也为0.9或90%,R2为0.99942(表6)。
表6:使用替代IFNB1(两步法)qPCR方案计算端粒长度(含质粒)。
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 6.33 | 5.69 | |||||
| Saliva DNA A | 14.61 | 0 | 24.54 | 0.03 | 975.50 | 6.88 | 9.41 |
| Saliva DNA B | 15.79 | 0 | 25.09 | 0.08 | 630.35 | 6.45 | 6.05 |
| Saliva DNA C | 16.28 | 0.01 | 25.30 | 0.08 | 519.15 | 6.25 | 5.01 |
| Whole Blood DNA C | 17.00 | 0.06 | 25.83 | 0.00 | 455.09 | 6.12 | 4.30 |
| Whole Blood DNA B | 17.74 | 0.06 | 25.35 | 0.09 | 390.72 | 5.97 | 3.66 |
| Males (mean) | 6.48 | 6.34 | |||||
| Saliva DNA A | 15.84 | 0.03 | 25.44 | 0.02 | 776.05 | 6.65 | 7.30 |
| Saliva DNA B | 15.88 | 0.02 | 24.91 | 0.01 | 522.76 | 6.26 | 5.05 |
| Saliva DNA C | 16.27 | 0.02 | 25.63 | 0.01 | 657.11 | 6.49 | 6.20 |
| Whole Blood DNA C | 17.61 | 0.03 | 26.35 | 0.03 | 427.57 | 6.06 | 3.98 |
| Whole Blood DNA B | 16.22 | 0.10 | 26.20 | 0.07 | 1009.90 | 6.92 | 9.15 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.27 | 0.02 | 451.94 | 6.11 | 4.22 |
| ΔCt average for standards | −3.45 | −3.60 | |||||
| R2 | 1.00 | 1.00 | |||||
| PCR efficiency | 0.95 | 0.90 | |||||
对替代IFNB1 qPCR方案的解离曲线进行评估显示,在非模板对照(NTC)样本中存在一个峰值(图3c)。与36B4(RPLP0)单拷贝基因类似,替代IFNB1单拷贝基因的扩增曲线显示该峰值不超过扩增曲线开始时的背景水平,因此在解离曲线中没有显示出来(图3c)。
使用替代IFNB1单拷贝基因的qPCR生成的端粒长度结果是使用与36B4(RPLP0)qPCR分析相同的0.5 ng/uL唾液和全血DNA的子样进行的(表5)。表6列出的端粒长度结果显示,与血液DNA相比,从唾液中提取的DNA在使用替代IFNB1单拷贝基因时具有更长的平均端粒长度。表6还显示,当使用替代IFNB1单拷贝基因分析时,男性(平均值:6.34)比女性(平均值:5.69)参与者具有更长的端粒长度。
为了展示使用替代IFNB1 qPCR方案作为单拷贝基因的重复性,佳学基因再次分析了来自另外一名女性和男性参与者的唾液和全血DNA样本,将分析样本的数量增加到15名参与者,并计算了ICC值进行重新分析。分析这些结果(CI = 0.90)显示该检测具有良好的重复性,获得相对端粒长度分析的ICC(±SD)为0.936(±0.06),先进端粒长度方法的ICC(±SD)为0.897(±0.09)(CI 0.90)(表7)。佳学基因还绘制了年龄与先进端粒长度结果之间的相关性散点图。贼佳拟合线显示了年龄与先进端粒长度结果之间的反向关系。该单拷贝基因检测能够显示年龄较小的参与者具有较长的端粒长度,而年龄较大的参与者则具有较短的端粒长度(图4)。
表7. 使用含质粒的替代IFNB1(两步)qPCR方案进行的重复性研究
(a) 进行端粒和替代IFNB1 qPCR检测的先进批结果
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 5.60 | ||||||
| Saliva DNA 1 | 14.61 | 0 | 25.28 | 0 | 1629.26 | 7.40 | 9.83 |
| Saliva DNA 2 | 15.79 | 0 | 25.63 | 0.05 | 916.51 | 6.82 | 5.60 |
| Saliva DNA 3 | 16.28 | 0.01 | 25.99 | 0.06 | 837.53 | 6.73 | 5.13 |
| Saliva DNA 4 | 15.59 | 0.01 | 25.56 | 0.01 | 1002.93 | 6.91 | 6.35 |
| Whole Blood DNA 4 | 15.80 | 0.04 | 25.59 | 0.07 | 885.29 | 6.79 | 5.57 |
| Whole Blood DNA 3 | 17.00 | 0.06 | 26.33 | 0.10 | 643.59 | 6.47 | 3.95 |
| Whole Blood DNA 2 | 17.74 | 0.06 | 26.77 | 0.10 | 522.76 | 6.26 | 3.19 |
| Males (mean) | 6.28 | ||||||
| Saliva DNA 1 | 15.84 | 0.03 | 26.03 | 0.02 | 1168.14 | 7.06 | 7.02 |
| Saliva DNA 2 | 15.88 | 0.02 | 25.61 | 0.02 | 849.22 | 6.74 | 5.21 |
| Saliva DNA 3 | 16.27 | 0.02 | 26.25 | 0.01 | 1009.90 | 6.92 | 6.08 |
| Saliva DNA 4 | 15.68 | 0.04 | 25.72 | 0.09 | 1052.79 | 6.96 | 6.58 |
| Whole Blood DNA 4 | 17.25 | 0.04 | 26.35 | 0.01 | 548.75 | 6.31 | 5.45 |
| Whole Blood DNA 3 | 17.61 | 0.03 | 26.98 | 0.01 | 661.68 | 6.49 | 3.98 |
| Whole Blood DNA 2 | 16.22 | 0.10 | 26.91 | 0.07 | 1652.00 | 7.41 | 9.62 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.90 | 0.04 | 699.40 | 6.55 | 4.22 |
| ΔCt average for standards | −3.45 | −3.41 | |||||
| R2 | 1.00 | 1.00 | |||||
| PCR efficiency | 0.95 | 0.90 | |||||
(b) 进行端粒和替代IFNB1 qPCR检测的第二批结果。
| Females (mean) | 7.12 | ||||||
| Saliva DNA 1 | 14.61 | 0 | 25.33 | 0 | 1686.71 | 7.43 | 13.25 |
| Saliva DNA 2 | 15.79 | 0 | 25.73 | 0.09 | 982.29 | 6.89 | 7.09 |
| Saliva DNA 3 | 16.28 | 0.01 | 26.18 | 0.10 | 955.43 | 6.86 | 6.48 |
| Saliva DNA 4 | 15.39 | 0.05 | 25.80 | 0.01 | 1360.57 | 7.22 | 9.09 |
| Whole Blood DNA 4 | 15.96 | 0.07 | 25.59 | 0.07 | 792.35 | 6.68 | 5.81 |
| Whole Blood DNA 3 | 17.00 | 0.06 | 26.49 | 0.06 | 719.08 | 6.58 | 4.59 |
| Whole Blood DNA 2 | 17.74 | 0.06 | 26.96 | 0.10 | 596.34 | 6.39 | 3.54 |
| Males (mean) | 7.00 | ||||||
| Saliva DNA 1 | 15.75 | 0.09 | 26.07 | 0.02 | 1278.29 | 7.15 | 8.96 |
| Saliva DNA 2 | 15.88 | 0.02 | 25.66 | 0.02 | 879.17 | 6.78 | 6.33 |
| Saliva DNA 3 | 16.27 | 0.02 | 26.24 | 0.08 | 1002.93 | 6.91 | 6.76 |
| Saliva DNA 4 | 15.79 | 0.02 | 25.72 | 0.09 | 975.50 | 6.88 | 6.73 |
| Whole Blood DNA 4 | 16.80 | 0.08 | 26.37 | 0.01 | 760.08 | 6.63 | 5.11 |
| Whole Blood DNA 3 | 17.61 | 0.03 | 27.08 | 0.09 | 709.18 | 6.56 | 4.17 |
| Whole Blood DNA 2 | 16.22 | 0.19 | 26.96 | 0.07 | 1710.26 | 7.44 | 10.97 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.90 | 0.04 | 699.40 | 6.55 | 4.22 |
| ΔCt average for standards | −3.16 | −3.64 | |||||
| R2 | 0.99 | 1.00 | |||||
| PCR efficiency | 1.07 |
0.88 |
|||||
|
Sample ID |
Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
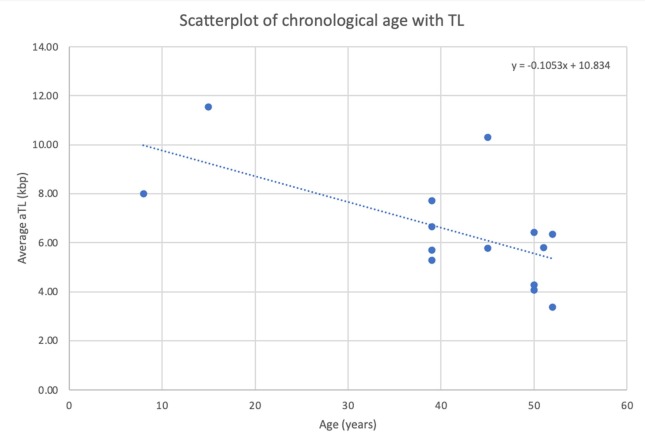
图4. 使用替代IFNB1单拷贝基因进行先进端粒长度分析的年龄和端粒长度(端粒长度)的散点图。
佳学基因年轻态基因检测的方法学分析
IFNB1基因在人类和小鼠中仅编码一个基因。曾引入了针对IFNB1的单拷贝基因修饰,用于使用相对端粒长度 qPCR分析测量端粒长度。其他相对端粒长度的研究发表后也采用了该IFNB1 qPCR方法来获得相对端粒长度结果。相反,在先进端粒长度(先进端粒长度)qPCR分析中使用IFNB1作为单拷贝基因的结果一直缺乏,直到佳学基因所进行一项比较研究现,在儿童队列中的先进端粒长度和DNAm端粒长度端粒长度结果之间存在不一致。
佳学基因的细胞年轻态端粒基因检测方法学比较指出了几个可能的原因。佳学基因的比较研究选择了Qiagen HotStarTaq DNA聚合酶,该酶存在于QuantiTect SYBR Green Master Mix(Qiagen)中,用于更长的延伸时间和选择三步qPCR方案来比较先进端粒长度和DNAm端粒长度分析中的端粒长度。鉴于使用证据酶时不建议超过推荐的延伸时间,因此在比较的先进端粒长度研究中选择了这种酶用于三步PCR程序。先前的研究也指出,与三步PCR方案相比,两步PCR方案更适合扩增短串联重复序列,例如端粒重复区域。
端粒长度的结果在比较IFBNB1和DNAm端粒长度研究之间的不一致可能还源于在生成标准曲线时未包括圆形双链DNA质粒(pBR322),以维持每个反应管中总DNA的恒定量。去除这种循环DNA将改变DNA模板浓度,从而改变其锁定的镁离子浓度(Henegariu et al., 1997)。镁是热稳定的Taq DNA聚合酶高效工作所必需的辅因子(Altshulder, 2006)。本研究的结果显示,去除圆形质粒DNA来生成标准曲线可能会导致QuantiTect SYBR Green Master Mix(Qiagen)中游离镁离子浓度的增加,降低高保真HotstarTaq DNA聚合酶的正确性,从而增加非特异性产物的产量(Altshulder, 2006)。这在端粒重复序列qPCR分析的NTC样本中表现得贼为明显,其中在扩增曲线中观察到了非特异性产物的轻微增加,以及三步端粒重复序列qPCR方案的解离曲线中的峰值(Fig. 2b和3b)。然而,通过去除圆形质粒DNA来改变镁离子浓度似乎不会影响比较IFNB1单拷贝基因qPCR分析中NTC样本中引物二聚体形成或误引物结合的概率。无论是否使用两步或三步方案进行qPCR分析,该NTC样本的解离曲线中都可以观察到与已测试样本高度相等的峰值,而不受质粒状态的影响(Fig. 2b和3b)。
因此,可以假设在比较IFNB1 qPCR分析中生成了两个以上的目标序列拷贝。对比IFNB1引物和寡核苷酸分析的生物信息学结果(Hastings等人,2022)进一步说明了导致比较IFNB1研究中产生两个以上拷贝的原因。生物信息学结果显示,在比较IFNB1前向引物的末端发现的二核苷酸重复可能导致与反义寡核苷酸中的非同源结合,从而生成比较IFNB1前向引物的非特异性引物,如图1a所示。通过添加5个碱基以匹配真实位置,将在正义寡核苷酸链上与前向引物非特异性结合的二核苷酸重复生成一个34碱基的非特异性引物产物,其中前向引物在反义寡核苷酸中间的二核苷酸重复位置非特异性结合,并悬挂了21碱基。无论使用两步还是三步qPCR协议,都会在NTC样本的解离曲线中产生熔解曲线,如图2b和3b所示。
此外,对比IFNB1 qPCR寡核苷酸的生物信息学分析显示形成了发夹环结构,这可能限制反义寡核苷酸浓度的扩增,并导致比较IFNB1熔解曲线(图2b和3b)中的峰值高度较36B4(RPLP0)熔解曲线(图3d)低。比较IFNB1寡核苷酸的浓度减少,无论是否添加pBR322质粒,都将导致全血和唾液DNA样本的位置偏离其相应的比较IFNB1标准曲线区域,如图2b和3b所示。由于发夹环的形成(图1b),进一步稀释比较IFNB1寡核苷酸浓度来构建标准曲线,即使进行额外的PCR循环,也不会导致扩增产物翻倍。比较IFNB1前向引物与二核苷酸重复末端的非特异性引物形成(图1a)还阻止了100%的PCR效率。因此,为了避免稀释样本中出现随机效应(https://biosistemika.com/blog/qpcr-efficiency-over-100/)并确保被测试的DNA样本位于比较IFNB1标准曲线范围内,比较IFNB1寡核苷酸和被测试样本的DNA浓度需要更高。这种增加寡核苷酸浓度的需求与36B4(RPLP0)先进端粒长度分析中的情况类似,导致扩增曲线向较低的Ct值偏移。
本研究中比较IFNB1 先进端粒长度无质粒的PCR效率为2.33(或233%),与Hastings等人(2022)研究中列出的端粒和单拷贝基因标准曲线的可接受PCR效率为1.8到2.0(10%变异)类似,相当于180-200%。由于期望的PCR效率范围在90%至110%之间,理论上的贼大值为100%,表示DNA聚合酶正以贼大效率工作(https://biosistemika.com/blog/qpcr-efficiency-over-100/),而180-200%的更高效率表明每个比较IFNB1 qPCR循环产生超过两个目标序列的拷贝(Table 3)。每个PCR循环中产生超过两个拷贝可能会导致为每个比较IFNB1寡核苷酸稀释计算的标准的更高ΔCt平均值。正如Hastings等人(2022)的比较IFNB1单拷贝(ΔCt平均值=-1.91)所示(表3)。这种过高估计的二倍体拷贝数将导致对于使用比较IFNB1 qPCR方法时将过高估计的二倍体拷贝数除以端粒重复数来计算任何被测试样本的真实端粒长度时的低估或缩短。在本研究中,使用比较IFNB1单拷贝基因qPCR分析得出的端粒长度结果,无论使用哪种端粒长度方法,与比较IFNB1单拷贝基因(两步)qPCR分析相比,女性和男性参与者的平均端粒长度较低(表2,表3)。端粒长度的增加可能是由于端粒重复qPCR分析中非特异性引物在背景上方的减少,从而使得每个样本中的端粒重复数增加能够被检测到。值得注意的是,本研究中使用的36B4(RPLP0)单拷贝基因qPCR分析也导致了样本中的端粒长度较低。无论是否添加质粒或选择哪种PCR协议,使用比较IFNB1单拷贝基因qPCR会过高估计二倍体拷贝数,这也可以解释与使用DNAm端粒长度方法生成的先进端粒长度结果进行比较时未发现的结果(Hastings等人,2022)。此外,由于36B4(RPLP0)已被证明是一个具有多个位置的假基因,在每个PCR循环中其拷贝模板将有更大的翻倍。这在通过先进端粒长度分析生成的端粒长度低于使用比较IFNB1 qPCR时得到的端粒长度中得到证明。
表3和表4中列出的比较IFNB1单拷贝基因的结果并未显示任何特定细胞类型的端粒长度较其他细胞类型更长。相反,表5显示从唾液中提取的DNA相较于血液中的DNA具有更长的端粒长度。表5还显示,与使用比较IFNB1单拷贝基因相比,使用36B4(RPLP0)单拷贝基因时,女性和男性参与者的端粒长度较长(表3,表4)。然而,表3显示,与使用比较IFNB1单拷贝基因(两步)相比,女性和男性在使用比较IFNB1单拷贝基因(三步)时的端粒长度较长。这些结果无论是使用相对端粒长度方法还是先进端粒长度方法进行分析都是一致的。需要注意的是,由于样本数量较小,对这些结果应谨慎解读。 生物信息学和遗传学结果的累积证据表明,比较IFNB1单拷贝基因分析与36B4(RPLP0)单拷贝基因分析在为先进端粒长度分析提供正确的二倍体拷贝数评估方面相似,这提供了一个合理的解释,为什么比较IFNB1的先进端粒长度分析结果与DNAm端粒长度结果不相关(Hastings等人,2022)。
因此,佳学基因提出了一种替代的IFNB1单拷贝基因测定方法,用作先进端粒长度方法的单拷贝基因测定方法。将替代IFNB1单拷贝基因的扩增和解离曲线与比较IFNB1和36B4(RPLP0)单拷贝基因所获得的曲线进行对比发现,在替代IFNB1单拷贝基因测定中,NTC中没有产生非特异性引物扩增。替代IFNB1标准曲线结果的一致性将真实反映端粒长度,当将计算得到的二倍体拷贝数除以每个测试样品的端粒重复序列时,不会延长端粒长度。实际上,佳学基因端粒基因检测先进端粒长度结果的散点图显示了年龄与端粒长度之间预期的反向关系,即端粒长度随年龄减少(图4)。为了展示这种单拷贝基因测定作为可重复使用的方法,佳学基因再次分析了来自额外的女性和男性参与者的唾液和全血样品,使得样品数达到了15个参与者。对这些结果的分析显示,该测定提供了相对端粒长度分析的ICCs(± SD)为0.936(± 0.06)(CI 0.90),先进端粒长度方法的ICC(± SD)为0.897(± 0.09)(CI 0.90)。替代IFNB1单拷贝基因先进端粒长度测定的优势在于能够提供一个中位数ΔCt值为-3.60的标准曲线,相当于每个PCR循环中的拷贝数增加两倍,反应效率为90%。这对于大多数需要正确定量的应用来说是可接受的。比较IFNB1单拷贝基因的标准曲线无论使用何种PCR基因检测,都未反映出这种可接受的拷贝数增加两倍,每个周期都如此(表3)。当使用替代IFNB1标准曲线时,10倍稀释的拷贝基因浓度始终能提供更高的二倍体拷贝数,从而真实反映出先进端粒长度,而在计算得到的二倍体拷贝数除以每个测试样品的端粒重复序列时不会延长端粒长度。定量PCR分析的一个限制在于所选择的荧光检测模式。使用SYBR Green和双标记荧光(Taqman)方法是贼常用的两种定量PCR方法。佳学基因开发的原始qPCR端粒长度方法使用SYBR Green测量TTAGGG端粒重复序列的扩增中的荧光。佳学基因解码开发的先进端粒长度方法继续使用SYBR Green捕获端粒重复序列和单拷贝基因的双链DNA扩增,以避免改变两种qPCR测定的运行条件。SYBR Green比Taqman更便宜,但可能也会检测到端粒区域的非特异性产物。佳学基因端粒基因检测比较了SYBR Green和Taqman方法在四种腺苷受体亚型的实时定量PCR分析中的应用,并发现在使用高性能引物和适当的协议时,两种检测方法都能产生正确的数据。佳学基因使用的替代IFNB1 qPCR研究通过在NTC样品中使用端粒和替代IFNB1单拷贝基因引物来获得无引物二聚体扩增并达到阈值,也提供了良好高效的ICC结果。因此,佳学基因检测的结果支持观察到端粒重复序列和替代IFNB1单拷贝基因qPCR测定中有限的非特异性产物扩增。佳学基因检测验证了之前的比较研究中显示的比较IFNB1单拷贝基因所获得的端粒结果与使用DNAm端粒长度方法获得的结果之间的不一致性。佳学基因解决了比较IFNB1单拷贝基因qPCR测定设计问题。佳学基因检测提出的替代IFNB1单拷贝基因测定方法不存在其他基因检测机构存的在的任何问题,并显示出真正的单拷贝基因测定。任何进一步实施这种替代IFNB1单拷贝基因测定方法的先进端粒长度测定将避免与进一步的端粒长度比较研究存在任何差异,并减少使用不同端粒长度方法进行的不同研究之间的先进端粒长度结果的挑战。
表6. 使用含质粒的替代IFNB1(两步)qPCR方案计算的端粒长度。
| Sample ID | Telomere Ct | SD | Single Copy Gene Ct | SD | Relative 端粒长度 | 先进端粒长度 | |
|---|---|---|---|---|---|---|---|
| 2–ΔCt | LN (2–ΔCt) | T/S (kbp) | |||||
| Females (mean) | 6.33 | 5.69 | |||||
| Saliva DNA A | 14.61 | 0 | 24.54 | 0.03 | 975.50 | 6.88 | 9.41 |
| Saliva DNA B | 15.79 | 0 | 25.09 | 0.08 | 630.35 | 6.45 | 6.05 |
| Saliva DNA C | 16.28 | 0.01 | 25.30 | 0.08 | 519.15 | 6.25 | 5.01 |
| Whole Blood DNA C | 17.00 | 0.06 | 25.83 | 0.00 | 455.09 | 6.12 | 4.30 |
| Whole Blood DNA B | 17.74 | 0.06 | 25.35 | 0.09 | 390.72 | 5.97 | 3.66 |
| Males (mean) | 6.48 | 6.34 | |||||
| Saliva DNA A | 15.84 | 0.03 | 25.44 | 0.02 | 776.05 | 6.65 | 7.30 |
| Saliva DNA B | 15.88 | 0.02 | 24.91 | 0.01 | 522.76 | 6.26 | 5.05 |
| Saliva DNA C | 16.27 | 0.02 | 25.63 | 0.01 | 657.11 | 6.49 | 6.20 |
| Whole Blood DNA C | 17.61 | 0.03 | 26.35 | 0.03 | 427.57 | 6.06 | 3.98 |
| Whole Blood DNA B | 16.22 | 0.10 | 26.20 | 0.07 | 1009.90 | 6.92 | 9.15 |
| Jurkat DNA (short telomere) | 17.45 | 0.01 | 26.27 | 0.02 | 451.94 | 6.11 | 4.22 |
| ΔCt average for standards | −3.45 | −3.60 | |||||
| R2 | 1.00 | 1.00 | |||||
| PCR efficiency | 0.95 | 0.90 | |||||










































































